Recently I have finished the work on understanding what exactly is the content of the GEOSS global data infrastructure.
Many partial approaches were shown in previous posts and this one concludes the outcome.
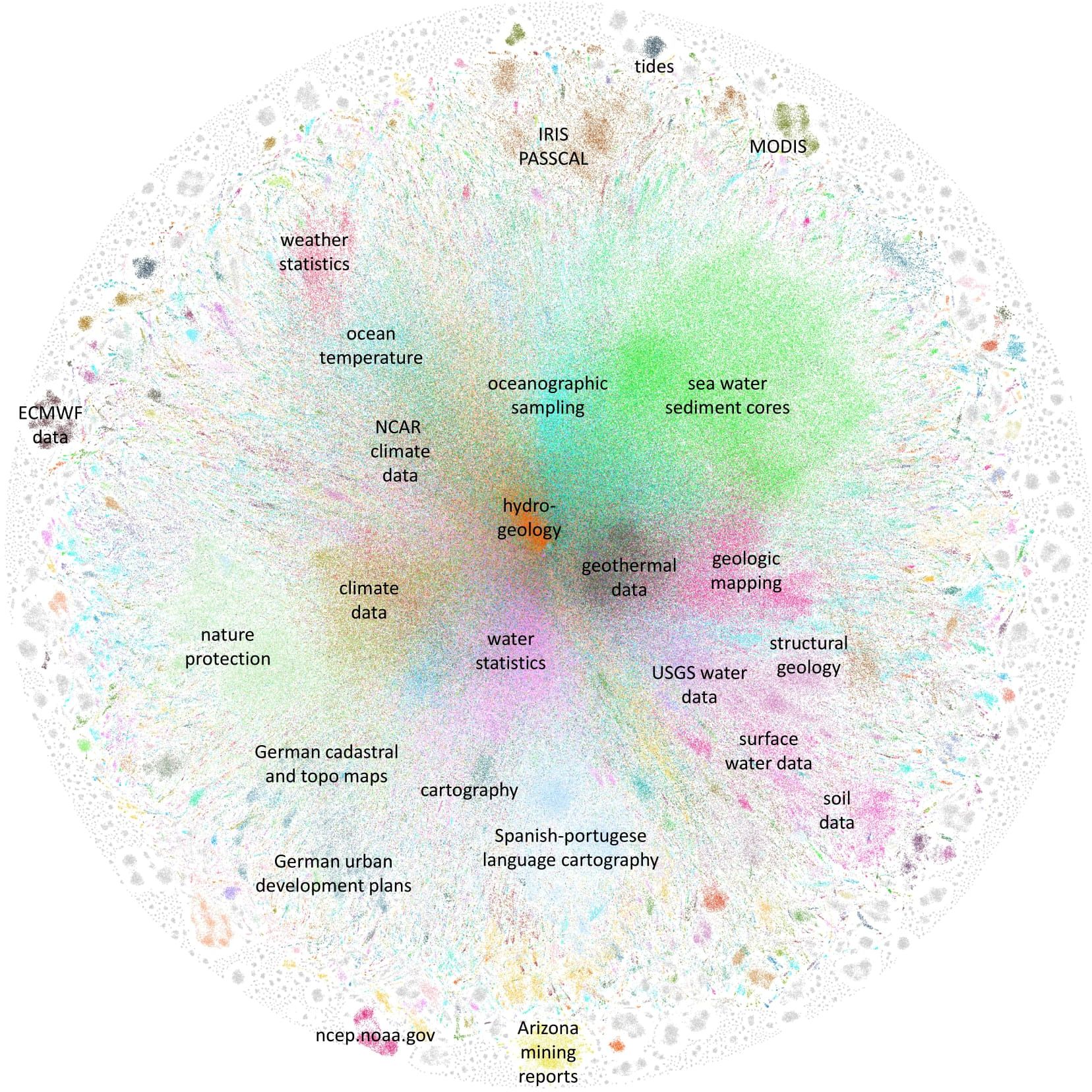
For all the 1.8M metadata records from GEOSS we calculated document vectors and tried to run cluster detection with cosine similarity as metrics. Matrix 1800000×500 resisted a lot so I just converted the document similarities to a network of three most similar ones and here is the outcome with detected communities. It fully represents the true content of the infrastructure now.